Problem definition
Making money on crypto is difficult and risky, but what if we could alleviate that issue. This is where predicting future values come into place. This is where recurrent neural networks come into picture, there are alot of studies that cover these algorithms and their performance, so they are well researched. Most used are LSTM, GRU and BILSTM, so of course question rises, which one is the superior to the others?
This was one of the questions in my final thesis, which we got the answer to.
Data collection and preprocessing
The first step was getting data and preprocessing it for fitting.
We got the data from binance, then since we decided to use univariate model, we removed every other column than the close value.
Second step is data normalization: we want to normalize the data from 0 to 1 for RNN algorithms.
Hyper parametering the data
We want to explain the way models are fitted for
forecasting the prices. The models are built to be uni-variate, meaning models take
into consideration only the past data of the close price.
To validate this, we use data points that were 6 days ahead of the training model.
This is so we can be more flexible with the buying strategies that take into account
further predictions beyond just one day. Next, we determine the appropriate set of
attributes that work for a window length of 6 days. This produces a prediction on the
19th day from the first data point. We computed the mean absolute percentage error
(MAPE) to determine the best description of the data for forecasting the prices. We
learned that we needed to have 13 features for predicting the price for a given day (in
one row). This is from having total time-series data of 152 rows for training. We do
this to minimize the MAPE without over-fitting the models at the same time.
From this we have used 145 days as training set and 6 days as a testing set.
RNNs models
All 3 models when training use batch size of 16, and 100 epochs and 13 neurons on
input layer.
We have used 100 epochs because it is a good number which doesn’t either over-train
or under-train the models and training time is reasonable which is also a factor.
Number of neurons of 13 in input layer is because there are 13 parameters which
are taken in as an input.
We have chosen batch size 16 instead of 13, even though final batch has fewer
samples to work through, the performance improved slightly with very little cost to
processing time.
The GRU model that is set up using one GRU layer and two dense layers.
The LSTM model is set up using two LSTM layers and two dense layers.
The BiLSTM model is set up using two BiLSTM layers and two dense layers.
While we hyperparametered, we needed to consider the time it took to fit and predict, so the performance might not be optimal, but the execution time is reasonable on mid-tier laptop.

As basis for this code we have used this code:
https://github.com/flo7up/relataly-public-python-tutorials/blob/master/003%20Time%20Series%20Forecasting%20-%20Univariate%20Model%20using%20Recurrent%20Neural%20Networks.ipynb
Results
So we have fitted the all 3 models with 9 cryptocurrencies, and we measured their performance in MAPE
Here is the table of results:
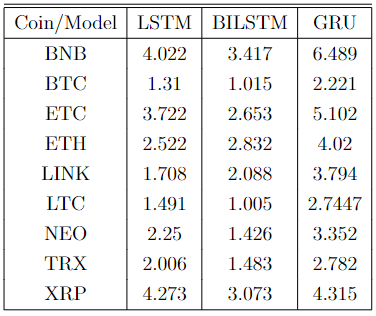
We have concluded that the BiLSTM is most efficient model as prediction goes. Although we cannot evaluate models strictly on MAPE, since this was one of the points on my final thesis, BILSTM turned out to be best model in most of the cases, since the predicting momentum correctly is more important than just MAPE or any other metric. This type of research is important if we want to invest in crypto and we want to optimize our portfolio.